Merge "Light refactoring of intrinsics calibration code"
diff --git a/aos/events/logging/buffer_encoder.cc b/aos/events/logging/buffer_encoder.cc
index 4b3ccf3..5c1d4b2 100644
--- a/aos/events/logging/buffer_encoder.cc
+++ b/aos/events/logging/buffer_encoder.cc
@@ -9,34 +9,32 @@
namespace aos::logger {
-DummyEncoder::DummyEncoder(size_t max_buffer_size) {
- // TODO(austin): This is going to end up writing > 128k chunks, not 128k
- // chunks exactly. If we really want to, we could make it always write 128k
- // chunks by only exposing n * 128k chunks as we go. This might improve write
- // performance, then again, it might have no effect if the kernel is combining
- // writes...
- constexpr size_t kWritePageSize = 128 * 1024;
+DummyEncoder::DummyEncoder(size_t /*max_message_size*/, size_t buffer_size) {
// Round up to the nearest page size.
- input_buffer_.reserve(
- ((max_buffer_size + kWritePageSize - 1) / kWritePageSize) *
- kWritePageSize);
+ input_buffer_.reserve(buffer_size);
return_queue_.resize(1);
}
-bool DummyEncoder::HasSpace(size_t request) const {
- return request + input_buffer_.size() < input_buffer_.capacity();
+size_t DummyEncoder::space() const {
+ return input_buffer_.capacity() - input_buffer_.size();
}
-void DummyEncoder::Encode(Copier *copy) {
- DCHECK(HasSpace(copy->size()));
+bool DummyEncoder::HasSpace(size_t request) const { return request <= space(); }
+
+size_t DummyEncoder::Encode(Copier *copy, size_t start_byte) {
const size_t input_buffer_initial_size = input_buffer_.size();
- input_buffer_.resize(input_buffer_initial_size + copy->size());
- const size_t written_size = copy->Copy(
- input_buffer_.data() + input_buffer_initial_size, 0, copy->size());
- DCHECK_EQ(written_size, copy->size());
+ size_t expected_write_size =
+ std::min(input_buffer_.capacity() - input_buffer_initial_size,
+ copy->size() - start_byte);
+ input_buffer_.resize(input_buffer_initial_size + expected_write_size);
+ const size_t written_size =
+ copy->Copy(input_buffer_.data() + input_buffer_initial_size, start_byte,
+ expected_write_size + start_byte);
total_bytes_ += written_size;
+
+ return written_size;
}
void DummyEncoder::Clear(const int n) {
diff --git a/aos/events/logging/buffer_encoder.h b/aos/events/logging/buffer_encoder.h
index f4a6251..ed5bef6 100644
--- a/aos/events/logging/buffer_encoder.h
+++ b/aos/events/logging/buffer_encoder.h
@@ -30,7 +30,7 @@
size_t size_;
};
- // Coppies a span. The span must have a longer lifetime than the coppier is
+ // Copies a span. The span must have a longer lifetime than the coppier is
// being used.
class SpanCopier : public Copier {
public:
@@ -55,12 +55,13 @@
// the output needs to be flushed.
virtual bool HasSpace(size_t request) const = 0;
- // Encodes and enqueues the given data encoder.
- virtual void Encode(Copier *copy) = 0;
+ // Returns the space available.
+ virtual size_t space() const = 0;
- // If this returns true, the encoder may be bypassed by writing directly to
- // the file.
- virtual bool may_bypass() const { return false; }
+ // Encodes and enqueues the given data encoder. Starts at the start byte
+ // (which must be a multiple of 8 bytes), and goes as far as it can. Returns
+ // the amount encoded.
+ virtual size_t Encode(Copier *copy, size_t start_byte) = 0;
// Finalizes the encoding process. After this, queue_size() represents the
// full extent of data which will be written to this file.
@@ -90,7 +91,7 @@
// and queues it up as is.
class DummyEncoder final : public DataEncoder {
public:
- DummyEncoder(size_t max_buffer_size);
+ DummyEncoder(size_t max_message_size, size_t buffer_size = 128 * 1024);
DummyEncoder(const DummyEncoder &) = delete;
DummyEncoder(DummyEncoder &&other) = delete;
DummyEncoder &operator=(const DummyEncoder &) = delete;
@@ -98,8 +99,8 @@
~DummyEncoder() override = default;
bool HasSpace(size_t request) const final;
- void Encode(Copier *copy) final;
- bool may_bypass() const final { return true; }
+ size_t space() const final;
+ size_t Encode(Copier *copy, size_t start_byte) final;
void Finish() final {}
void Clear(int n) final;
absl::Span<const absl::Span<const uint8_t>> queue() final;
diff --git a/aos/events/logging/buffer_encoder_param_test.h b/aos/events/logging/buffer_encoder_param_test.h
index 9e7882d..6085779 100644
--- a/aos/events/logging/buffer_encoder_param_test.h
+++ b/aos/events/logging/buffer_encoder_param_test.h
@@ -45,7 +45,7 @@
<< encoder->queued_bytes() << ", encoding " << buffer.size();
DetachedBufferCopier coppier(std::move(buffer));
- encoder->Encode(&coppier);
+ encoder->Encode(&coppier, 0);
}
return result;
}
diff --git a/aos/events/logging/buffer_encoder_test.cc b/aos/events/logging/buffer_encoder_test.cc
index 5f3ecab..d5e2e5d 100644
--- a/aos/events/logging/buffer_encoder_test.cc
+++ b/aos/events/logging/buffer_encoder_test.cc
@@ -13,9 +13,12 @@
class DummyEncoderTest : public BufferEncoderBaseTest {};
+constexpr size_t kEncoderBufferSize = 4 * 1024 * 1024;
+
// Tests that buffers are concatenated without being modified.
TEST_F(DummyEncoderTest, QueuesBuffersAsIs) {
- DummyEncoder encoder(BufferEncoderBaseTest::kMaxMessageSize);
+ DummyEncoder encoder(BufferEncoderBaseTest::kMaxMessageSize,
+ kEncoderBufferSize);
const auto expected = CreateAndEncode(100, &encoder);
std::vector<uint8_t> data = Flatten(expected);
@@ -26,7 +29,8 @@
// Tests that buffers are concatenated without being modified.
TEST_F(DummyEncoderTest, CoppiesBuffersAsIs) {
- DummyEncoder encoder(BufferEncoderBaseTest::kMaxMessageSize);
+ DummyEncoder encoder(BufferEncoderBaseTest::kMaxMessageSize,
+ kEncoderBufferSize);
const auto expected = CreateAndEncode(100, &encoder);
std::vector<uint8_t> data = Flatten(expected);
@@ -108,7 +112,8 @@
INSTANTIATE_TEST_SUITE_P(
Dummy, BufferEncoderTest,
::testing::Combine(::testing::Values([](size_t max_buffer_size) {
- return std::make_unique<DummyEncoder>(max_buffer_size);
+ return std::make_unique<DummyEncoder>(
+ max_buffer_size, kEncoderBufferSize);
}),
::testing::Values([](std::string_view filename) {
return std::make_unique<DummyDecoder>(filename);
diff --git a/aos/events/logging/log_namer.cc b/aos/events/logging/log_namer.cc
index c0c7c73..86d813f 100644
--- a/aos/events/logging/log_namer.cc
+++ b/aos/events/logging/log_namer.cc
@@ -14,6 +14,8 @@
#include "flatbuffers/flatbuffers.h"
#include "glog/logging.h"
+DECLARE_int32(flush_size);
+
namespace aos {
namespace logger {
@@ -568,7 +570,12 @@
EventLoop *event_loop, const Node *node)
: LogNamer(configuration, event_loop, node),
base_name_(base_name),
- old_base_name_() {}
+ old_base_name_(),
+ encoder_factory_([](size_t max_message_size) {
+ // TODO(austin): For slow channels, can we allocate less memory?
+ return std::make_unique<DummyEncoder>(max_message_size,
+ FLAGS_flush_size);
+ }) {}
MultiNodeLogNamer::~MultiNodeLogNamer() {
if (!ran_out_of_space_) {
diff --git a/aos/events/logging/log_namer.h b/aos/events/logging/log_namer.h
index 4e8c990..07edeac 100644
--- a/aos/events/logging/log_namer.h
+++ b/aos/events/logging/log_namer.h
@@ -491,10 +491,7 @@
std::vector<std::string> all_filenames_;
std::string temp_suffix_;
- std::function<std::unique_ptr<DataEncoder>(size_t)> encoder_factory_ =
- [](size_t max_message_size) {
- return std::make_unique<DummyEncoder>(max_message_size);
- };
+ std::function<std::unique_ptr<DataEncoder>(size_t)> encoder_factory_;
std::string extension_;
// Storage for statistics from previously-rotated DetachedBufferWriters.
diff --git a/aos/events/logging/logfile_utils.cc b/aos/events/logging/logfile_utils.cc
index 0918545..86c89a8 100644
--- a/aos/events/logging/logfile_utils.cc
+++ b/aos/events/logging/logfile_utils.cc
@@ -129,7 +129,7 @@
return *this;
}
-void DetachedBufferWriter::CopyMessage(DataEncoder::Copier *coppier,
+void DetachedBufferWriter::CopyMessage(DataEncoder::Copier *copier,
aos::monotonic_clock::time_point now) {
if (ran_out_of_space_) {
// We don't want any later data to be written after space becomes
@@ -138,12 +138,23 @@
return;
}
- if (!encoder_->HasSpace(coppier->size())) {
- Flush();
- CHECK(encoder_->HasSpace(coppier->size()));
- }
+ const size_t message_size = copier->size();
+ size_t overall_bytes_written = 0;
- encoder_->Encode(coppier);
+ // Keep writing chunks until we've written it all. If we end up with a
+ // partial write, this means we need to flush to disk.
+ do {
+ const size_t bytes_written = encoder_->Encode(copier, overall_bytes_written);
+ CHECK(bytes_written != 0);
+
+ overall_bytes_written += bytes_written;
+ if (overall_bytes_written < message_size) {
+ VLOG(1) << "Flushing because of a partial write, tried to write "
+ << message_size << " wrote " << overall_bytes_written;
+ Flush(now);
+ }
+ } while (overall_bytes_written < message_size);
+
FlushAtThreshold(now);
}
@@ -153,7 +164,7 @@
}
encoder_->Finish();
while (encoder_->queue_size() > 0) {
- Flush();
+ Flush(monotonic_clock::max_time);
}
if (close(fd_) == -1) {
if (errno == ENOSPC) {
@@ -166,7 +177,8 @@
VLOG(1) << "Closed " << filename();
}
-void DetachedBufferWriter::Flush() {
+void DetachedBufferWriter::Flush(aos::monotonic_clock::time_point now) {
+ last_flush_time_ = now;
if (ran_out_of_space_) {
// We don't want any later data to be written after space becomes available,
// so refuse to write anything more once we've dropped data because we ran
@@ -260,13 +272,14 @@
// Flush if we are at the max number of iovs per writev, because there's no
// point queueing up any more data in memory. Also flush once we have enough
// data queued up or if it has been long enough.
- while (encoder_->queued_bytes() > static_cast<size_t>(FLAGS_flush_size) ||
+ while (encoder_->space() == 0 ||
+ encoder_->queued_bytes() > static_cast<size_t>(FLAGS_flush_size) ||
encoder_->queue_size() >= IOV_MAX ||
now > last_flush_time_ +
chrono::duration_cast<chrono::nanoseconds>(
chrono::duration<double>(FLAGS_flush_period))) {
- last_flush_time_ = now;
- Flush();
+ VLOG(1) << "Chose to flush at " << now << ", last " << last_flush_time_;
+ Flush(now);
}
}
diff --git a/aos/events/logging/logfile_utils.h b/aos/events/logging/logfile_utils.h
index 4e38feb..1dbcbd8 100644
--- a/aos/events/logging/logfile_utils.h
+++ b/aos/events/logging/logfile_utils.h
@@ -134,12 +134,13 @@
private:
// Performs a single writev call with as much of the data we have queued up as
- // possible.
+ // possible. now is the time we flushed at, to be recorded in
+ // last_flush_time_.
//
// This will normally take all of the data we have queued up, unless an
// encoder has spit out a big enough chunk all at once that we can't manage
// all of it.
- void Flush();
+ void Flush(aos::monotonic_clock::time_point now);
// write_return is what write(2) or writev(2) returned. write_size is the
// number of bytes we expected it to write.
diff --git a/aos/events/logging/logger_main.cc b/aos/events/logging/logger_main.cc
index 81b4e3f..f0582dc 100644
--- a/aos/events/logging/logger_main.cc
+++ b/aos/events/logging/logger_main.cc
@@ -32,6 +32,8 @@
DEFINE_int32(xz_compression_level, 9, "Compression level for the LZMA Encoder");
#endif
+DECLARE_int32(flush_size);
+
int main(int argc, char *argv[]) {
gflags::SetUsageMessage(
"This program provides a simple logger binary that logs all SHMEM data "
@@ -53,14 +55,15 @@
if (FLAGS_snappy_compress) {
log_namer->set_extension(aos::logger::SnappyDecoder::kExtension);
log_namer->set_encoder_factory([](size_t max_message_size) {
- return std::make_unique<aos::logger::SnappyEncoder>(max_message_size);
+ return std::make_unique<aos::logger::SnappyEncoder>(max_message_size,
+ FLAGS_flush_size);
});
#ifdef LZMA
} else if (FLAGS_xz_compress) {
log_namer->set_extension(aos::logger::LzmaEncoder::kExtension);
log_namer->set_encoder_factory([](size_t max_message_size) {
return std::make_unique<aos::logger::LzmaEncoder>(
- max_message_size, FLAGS_xz_compression_level);
+ max_message_size, FLAGS_xz_compression_level, FLAGS_flush_size);
});
#endif
}
diff --git a/aos/events/logging/logger_test.cc b/aos/events/logging/logger_test.cc
index 18c8aa1..cdf080b 100644
--- a/aos/events/logging/logger_test.cc
+++ b/aos/events/logging/logger_test.cc
@@ -557,7 +557,7 @@
}},
{SnappyDecoder::kExtension,
[](size_t max_message_size) {
- return std::make_unique<SnappyEncoder>(max_message_size);
+ return std::make_unique<SnappyEncoder>(max_message_size, 32768);
}},
#ifdef LZMA
{LzmaDecoder::kExtension,
diff --git a/aos/events/logging/lzma_encoder.cc b/aos/events/logging/lzma_encoder.cc
index 3959727..f354638 100644
--- a/aos/events/logging/lzma_encoder.cc
+++ b/aos/events/logging/lzma_encoder.cc
@@ -88,19 +88,22 @@
LzmaEncoder::~LzmaEncoder() { lzma_end(&stream_); }
-void LzmaEncoder::Encode(Copier *copy) {
+size_t LzmaEncoder::Encode(Copier *copy, size_t start_byte) {
const size_t copy_size = copy->size();
// LZMA compresses the data as it goes along, copying the compressed results
// into another buffer. So, there's no need to store more than one message
// since lzma is going to take it from here.
CHECK_LE(copy_size, input_buffer_.size());
- CHECK_EQ(copy->Copy(input_buffer_.data(), 0, copy_size), copy_size);
+ CHECK_EQ(copy->Copy(input_buffer_.data(), start_byte, copy_size - start_byte),
+ copy_size - start_byte);
stream_.next_in = input_buffer_.data();
stream_.avail_in = copy_size;
RunLzmaCode(LZMA_RUN);
+
+ return copy_size - start_byte;
}
void LzmaEncoder::Finish() { RunLzmaCode(LZMA_FINISH); }
diff --git a/aos/events/logging/lzma_encoder.h b/aos/events/logging/lzma_encoder.h
index bbd739a..b4964fb 100644
--- a/aos/events/logging/lzma_encoder.h
+++ b/aos/events/logging/lzma_encoder.h
@@ -37,7 +37,8 @@
// space.
return true;
}
- void Encode(Copier *copy) final;
+ size_t space() const final { return input_buffer_.capacity(); }
+ size_t Encode(Copier *copy, size_t start_byte) final;
void Finish() final;
void Clear(int n) final;
absl::Span<const absl::Span<const uint8_t>> queue() final;
diff --git a/aos/events/logging/snappy_encoder.cc b/aos/events/logging/snappy_encoder.cc
index 1b80fe0..0e96092 100644
--- a/aos/events/logging/snappy_encoder.cc
+++ b/aos/events/logging/snappy_encoder.cc
@@ -43,12 +43,15 @@
void SnappyEncoder::Finish() { EncodeCurrentBuffer(); }
-void SnappyEncoder::Encode(Copier *copy) {
+size_t SnappyEncoder::Encode(Copier *copy, size_t start_byte) {
+ CHECK_EQ(start_byte, 0u);
buffer_source_.Append(copy);
if (buffer_source_.Available() >= chunk_size_) {
EncodeCurrentBuffer();
}
+
+ return copy->size();
}
void SnappyEncoder::EncodeCurrentBuffer() {
diff --git a/aos/events/logging/snappy_encoder.h b/aos/events/logging/snappy_encoder.h
index d3edbe5..d698ee1 100644
--- a/aos/events/logging/snappy_encoder.h
+++ b/aos/events/logging/snappy_encoder.h
@@ -16,9 +16,9 @@
// Encodes buffers using snappy.
class SnappyEncoder final : public DataEncoder {
public:
- explicit SnappyEncoder(size_t max_message_size, size_t chunk_size = 32768);
+ explicit SnappyEncoder(size_t max_message_size, size_t chunk_size = 128 * 1024);
- void Encode(Copier *copy) final;
+ size_t Encode(Copier *copy, size_t start_byte) final;
void Finish() final;
void Clear(int n) final;
@@ -28,6 +28,7 @@
// Since the output always mallocs space, we have infinite output space.
return true;
}
+ size_t space() const final { return buffer_source_.space(); }
size_t total_bytes() const final { return total_bytes_; }
size_t queue_size() const final { return queue_.size(); }
@@ -35,6 +36,7 @@
class DetachedBufferSource : public snappy::Source {
public:
DetachedBufferSource(size_t buffer_size);
+ size_t space() const { return data_.capacity() - data_.size(); }
size_t Available() const final;
const char *Peek(size_t *length) final;
void Skip(size_t n) final;
diff --git a/documentation/README.md b/documentation/README.md
index 32b8eb1..0f6485c 100644
--- a/documentation/README.md
+++ b/documentation/README.md
@@ -13,3 +13,4 @@
* [Create a new autonomous routine](tutorials/create-a-new-autonomous.md)
* [Tune an autonomous](tutorials/tune-an-autonomous.md)
* [Set up access to the build server using vscode](tutorials/setup-ssh-vscode.md)
+* [Install PyCharm on the build server](tutorials/setup-pycharm-on-build-server.md)
diff --git a/documentation/tutorials/setup-pycharm-on-build-server.md b/documentation/tutorials/setup-pycharm-on-build-server.md
new file mode 100644
index 0000000..acbb66d
--- /dev/null
+++ b/documentation/tutorials/setup-pycharm-on-build-server.md
@@ -0,0 +1,20 @@
+## Installing PyCharm on the build server
+
+### Getting PyCharm Professional (optional)
+Go to JetBrains' student [website](https://www.jetbrains.com/community/education/#students) and click "Apply now". Fill out the form using your school email. Check your school email for an email from JetBrains. Create a new JetBrains account. Use this account to log in when PyCharn asks for a professional key
+
+### Downloading on the build server
+Open your shell and run
+```
+curl https://raw.githubusercontent.com/thealtofwar/files/main/install_pycharm.sh > ~/install_pycharm.sh
+chmod +x ~/install_pycharm.sh
+~/install_pycharm.sh
+```
+This installs PyCharm to your desktop.
+### Alternate download method
+When you're on the build server, go to the [download](https://www.jetbrains.com/pycharm/download/#section=linux) and pick which edition of PyCharm you would like to download. Once the download completes, click on it to extract it. When something that looks like this appears,<br>
+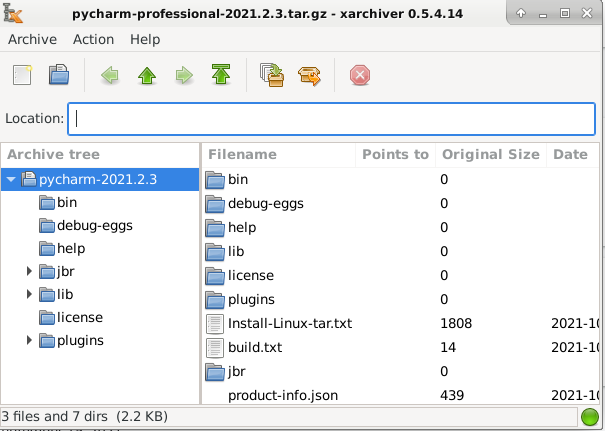<br>
+Look for the button that looks like a up arrow with a line of top that's labeled root that looks like [this](https://raw.githubusercontent.com/thealtofwar/files/main/Screenshot%202021-11-11%20101425.png). Click on it. Drag the folder to your desktop. It will say an error occured, but it should be fine.
+
+### Installing PyCharm on the build server
+When you're on the build server, go to the folder that you just downloaded PyCharm to. Click on the 'bin' folder. Click on the 'pycharm.sh' file. PyCharm should start running. If you downloaded the Professional version, you might have to log in with the JetBrains account you made when signing up. Open the folder where your project is located. Now you can start coding.
diff --git a/frc971/control_loops/python/graph.py b/frc971/control_loops/python/graph.py
index 178b63d..1cc6f57 100644
--- a/frc971/control_loops/python/graph.py
+++ b/frc971/control_loops/python/graph.py
@@ -49,12 +49,15 @@
if self.data is None:
return None
cursor_index = int(self.cursor / self.dt)
- if cursor_index > self.data.size:
+ if self.data[0].size < cursor_index:
return None
# use the time to index into the position data
- distance_at_cursor = self.data[0][cursor_index - 1]
- multispline_index = int(self.data[5][cursor_index - 1])
- return (multispline_index, distance_at_cursor)
+ try:
+ distance_at_cursor = self.data[0][cursor_index - 1]
+ multispline_index = int(self.data[5][cursor_index - 1])
+ return (multispline_index, distance_at_cursor)
+ except IndexError:
+ return None
def place_cursor(self, multispline_index, distance):
"""Places the cursor at a certain distance along the spline"""
diff --git a/frc971/control_loops/python/path_edit.py b/frc971/control_loops/python/path_edit.py
index 0a944e1..2b55e94 100755
--- a/frc971/control_loops/python/path_edit.py
+++ b/frc971/control_loops/python/path_edit.py
@@ -240,8 +240,11 @@
multispline, result = Multispline.nearest_distance(
self.multisplines, mouse)
- if self.graph.cursor is not None and self.graph.data is not None:
- multispline_index, x = self.graph.find_cursor()
+ if self.graph.cursor is not None:
+ cursor = self.graph.find_cursor()
+ if cursor is None:
+ return
+ multispline_index, x = cursor
distance_spline = DistanceSpline(
self.multisplines[multispline_index].getLibsplines())